Abstract
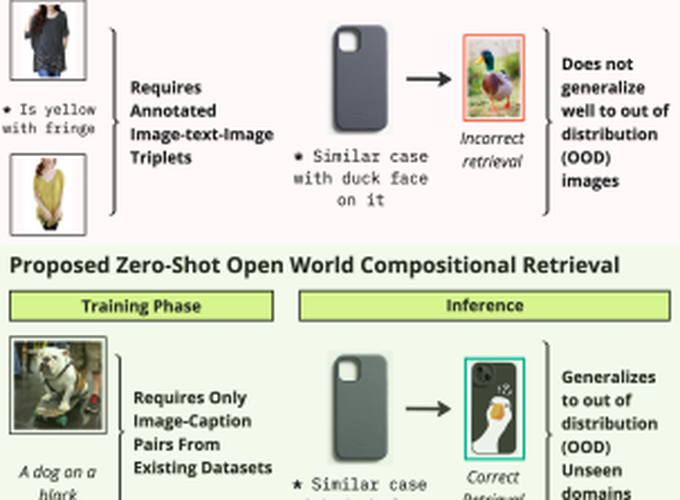
Compositional image retrieval (CIR) is a multimodal learning task where a model combines a query image with a user-provided text modification to retrieve a target image. CIR finds applications in a variety of domains including product retrieval (e-commerce) and web search. Existing methods primarily focus on fully-supervised learning, wherein models are trained on datasets of labeled triplets such as FashionIQ and CIRR. This poses two significant challenges: (i) curating such triplet datasets is labor intensive; and (ii) models lack generalization to unseen objects and domains. In this work, we propose SCOT (Self-supervised COmpositional Training), a novel zero-shot compositional pretraining strategy that combines existing large image-text pair datasets with the generative capabilities of large language models to contrastively train an embedding composition network. Specifically, we show that the text embedding from a large-scale contrastively-pretrained vision-language model can be utilized as proxy target supervision during compositional pretraining, replacing the target image embedding. In zero-shot settings, this strategy surpasses SOTA zero-shot compositional retrieval methods as well as many fully-supervised methods on standard benchmarks such as FashionIQ and CIRR.