Biography
I am a Research Scientist at Netflix Research, working on Multimodal Large Language Models, Reward Modeling, and Reasoning. I did my Ph.D. in Computer Science from the University at Buffalo, where I was advised by Dr. Venu Govindaraju. During my Ph.D., I was a part of the Center for Unified Biometrics and Sensors (CUBS) Lab.
Previously, I was a research scientist intern at Netflix Research, Yahoo Research, and Adobe Research. My doctoral research primarily focused on Multimodal Contrastive Learning, Deep Metric Learning, and Deep Feature Fusion. My Ph.D. was funded by the IARPA BRIAR, NSF AI Institute, Qualcomm, NSF CITeR, NSF DiBBS, and NSF S&CC programs.
Among some notable achievements, I received the IEEE Best Paper Award at IJCB 2023, the Graduate Leadership Award (2023) and the Russell Agrusa Research Innovation Award (2021), as well as the Best CSE Ph.D. Poster and SEAS Ph.D. Poster Awards in 2022.
- Nov 2025: I am hiring a Research Intern for summer 2026 at Netflix Research. Reach out if you are interesed.
- Nov 2025: Serving as an Area Chair for ICASSP 2026
- Feb 2025: Glad to share that I have joined Netflix Research as full-time Research Scientist
- Nov 2024: Glad to share that I our paper at Netflix Research - "RSMS: Audio-Visual Representation Learning For Lip-Sync Estimation Through Ranking Augmented Contrastive Training" was accepted at ICASSP 2025
- Oct 2024: Glad to share our paper 'ProxyFusion: Face Feature Aggregation Through Sparse Experts' got accepted at NeurIPS 2024
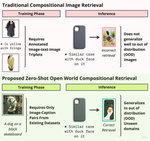
- August 2024: Glad to share our paper 'SCOT: Self-Supervised Contrastive Pre-training For Zero-Shot Compositional Retrieval' got accepted at WACV 2025 in Round 1 (12.1% Acceptance Rate)
- May 2024: Started summer internship at Netflix Research as a Research Scientist.
- Dec 2023: Honored to receive the Graduate Leadership Award, from Department of Computer Science, University at Buffalo
- Feb 2024: Glad to share our paper 'GestSpoof: Gesture Based Spatio-Temporal Representation Learning For Robust Fingerprint Presentation Attack Detection.' got accepted at FG 2024
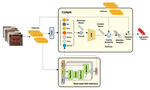
- Dec 2023: Glad to share our paper 'Conditional Neural Aggregation Network For Unconstrained Long Range Person Feature Fusion' got accepted in IEEE TBIOM Journal
- Sept 2023: CoNAN received the Best Paper Award at IJCB 2023. Link
- July 2023: Glad to share our paper title: 'CoNAN - Conditional Neural Aggregation Network for Unconstrained face recognition' has been accepted at IJCB 2023.
- May 2023: Started summer internship at Yahoo Research as a Research Scientist.
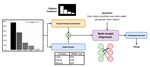
- April 2023: Glad to share our paper 'RealCQA - Scientific Chart Question Answering as a Test-bed for First-Order Logic' got accepted at ICDAR 2023.
- April 2023: Presented my work on spatio-temporal fingerprint spoof detection at CITeR-EAB workshop at Idiap, Switzerland.
- Feb 2023: Honored as one of the winner of SEAS PhD Research Poster Award 2023, by School of Engineering and Applied Sciences, at University at Buffalo
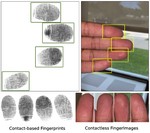
- Feb 2023: I will be co-organizing the IJCB LivDet 2023 Challenge on detecting contactless fingerprint spoofs.
- Feb 2023: Our book chapter on Deep Metric Learning in Handbook Of Statistics is now available online.
- Jan 2023: Met with SUNY Chancellor Dr. John B King (Former US Secretary of Education) as part of his visit to UB.
- Jan 2023: Presented our two papers (NAPReg and Hear The Flow) at WACV 2023 in Hawaii.
- Dec 2022: Awarded Best CSE PhD Poster Award 2022 by University at Buffalo
- Dec 2022: Presented our work on multi-modal fusion and feature aggregation (CoNAN) at IARPA BRIAR program review
- Nov 2022: Presented our work on fingerprint spoof detection through temporal learning at NSF CITeR's Fall 2022 Conference
- Oct 2022: Glad to share our paper 'NAP Regularization' got accepted at WACV 2023
- Oct 2022: Glad to share our paper 'Hear the Flow' got accepted at WACV 2023
- Oct 2022: Glad to share our paper on attribute de-biased vision transformers (AD-ViT) got accepted at AVSS 2022
- Oct 2022: Presented our paper on RidgeBase dataset at IJCB 2022
- Sep 2022: Our dataset RidgeBase is now available for public use
- Sep 2022: Presented our work on contactless fingerprint recongition at FedID conference
- Jun 2022: Won of the winners of Adobe Code Jam 2022
- May 2022: Started summer internship at Adobe Research as Research Scientist
- Dec 2021: Awarded Russell Agrusa Research Innovation Award
- Oct 2021: Won Blackstone launchpad Best Idea Award 2021
- Aug 2021: Started serving as the President of Computer Science Graduate Student Association
- Jun 2021: Glad to share our paper 'MultiLoss Fusion For Contactless Fingerprinting' got accepted at WIFS 2021
- Jan 2021: Won Govt. of British Columbia's Maple Ridge Hackathon
Interests
- Large Language Models
- Computer Vision
- Vision Language Alignment
- Deep Metric Learning
- Multi-modal Learning
- Machine Learning
Education
-
Ph.D. in Computer Science and Engineering, 2024
University at Buffalo, State University of New York
-
M.S. in Computer Science and Engineering, 2022
University at Buffalo, State University of New York
-
B.E. in Information Technology, 2019
SGSITS Indore
-
Secondary School, PCM - CS, 2015
S.T. Paul H.S. School Indore