
Before we get started
Read this article on Towards Data Science
Follow me on medium: https://bhavinjawade.medium.com/
Introduction
In the previous article on training large-scale models, we looked at LoRA. In this article, we will examine another strategy adopted by different large language models for efficient training — Grouped Query Attention (GQA). In short, Grouped Query Attention (GQA) is a generalization of multi-head attention (MHA) and multi-query attention (MQA) — with each of them being a special case of GQA. Therefore, before we dive into Grouped Query Attention, let’s revisit traditional multi-head attention proposed by Vaswani et al. in the seminal “Attention is All You Need” paper. Following that, we will explore Multi-query attention and how it addresses challenges with MHA. Finally, we will answer the questions “What is GQA?” and “How does it give us the best of both worlds?”
Multi-head Attention
Multi-head attention is a critical component of Transformer models, enabling them to efficiently process and understand complex sequences in tasks like language translation, summarization, and more. To grasp its intricacies, we must delve into the mathematical underpinnings and understand how multiple heads in the attention mechanism function.
The basic attention mechanism computes a weighted sum of values, with weights dependent on a query and a set of keys. Mathematically, this is expressed as:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
This is referred to as scaled dot product attention. In this equation, Q (Query) and K (Key) are matrices representing the queries and keys. V (Value) is the matrix for values. “d_k” is the dimensionality of keys, which is used for scaling.
Expanding with Multi-Head Attention (MHA)
Multi-head attention employs multiple ‘heads’ of attention layers, enabling the model to attend to information from different representation subspaces. In each head, there is an independent set of linear layers (projection matrices) for the query, key, and values (this is an important point that we will revisit in GQA). For each head (numbered h):
$$ headʰ = Attention(Q.Wqʰ,K.Wkʰ,V.Wvʰ) $$ shell Copy code
Concatenating Head Outputs
The outputs of the individual heads are concatenated and then linearly transformed.
$$ MultiHead(Q,K,V) = Concat(head¹,head²,…,headʰ) .Wᵒ $$
Wᵒ is another weight matrix that linearly transforms the concatenated vector to the final output dimension.
The intuition behind multi-head attention is that by applying the attention mechanism multiple times in parallel, the model can capture different types of relationships in the data.
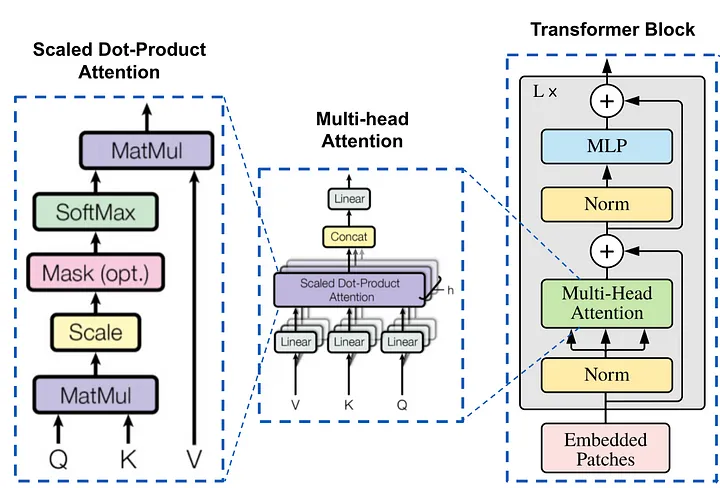 Source: Sections of the diagram from “Attention is All You Need” paper [https://arxiv.org/abs/1706.03762], composition by the author
Source: Sections of the diagram from “Attention is All You Need” paper [https://arxiv.org/abs/1706.03762], composition by the author
The Memory Bandwidth Challenge in Multi-Head Attention
The crux of the issue lies in the memory overhead. Each decoding step in autoregressive models like Transformers requires loading decoder weights along with all attention keys and values. This process is not only computationally intensive but also memory bandwidth-intensive. As model sizes grow, this overhead also increases, making scaling up an increasingly arduous task.
Emergence of Multi-Query Attention (MQA)
Multi-query attention (MQA) emerged as a solution to mitigate this bottleneck. The idea is simple yet effective: use multiple query heads but only a single key and value head. This approach significantly reduces the memory load, enhancing inference speed. It has been employed in multiple large-scale models such as PaLM, StarCoder, and Falcon.
In multi-query attention, we average the heads for keys and values so that all query heads share the same key and value head. This is achieved by replicating the mean-pooled “head” H times, where H is the number of query heads.
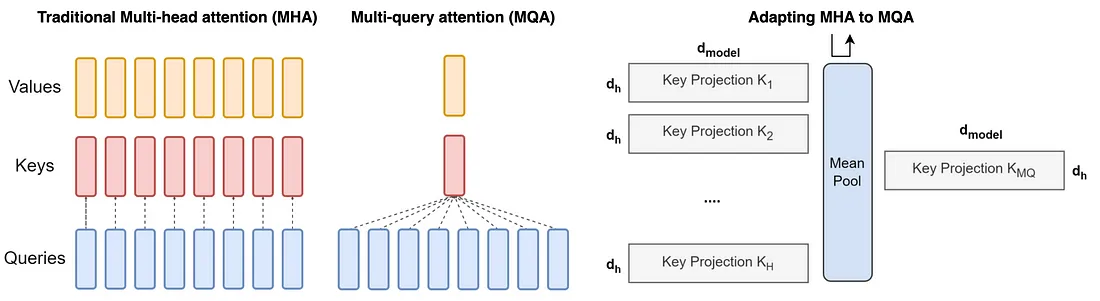 Source: https://arxiv.org/pdf/2305.13245.pdf
Source: https://arxiv.org/pdf/2305.13245.pdf
Grouped Query Attention
Grouped-query attention (GQA) is a simple approach that blends elements of multi-head attention (MHA) and multi-query attention (MQA) to create a more efficient attention mechanism. The mathematical framework of GQA can be understood as follows:
Division into Groups
In GQA, the query heads (Q) from a traditional multi-head model are divided into G groups. Each group is assigned a single key (K) and value (V) head. This configuration is denoted as GQA-G, where G represents the number of groups.
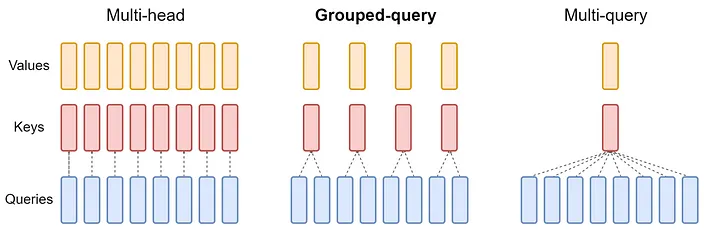 Source: https://arxiv.org/pdf/2305.13245.pdf
Source: https://arxiv.org/pdf/2305.13245.pdf
Conclusion
In this post, we first looked at traditional multi-head attention (MHA) and its variant Multi-query attention. Then we looked at a more generic formulation GQA, which is used by many LLM models for effective pre-training. GQA combines multi-head attention (MHA) with multi-query attention (MQA), providing a fair trade-off between quality and speed. GQA minimizes memory bandwidth demands by grouping query heads, making it appropriate for scaling up models. GQA has been used in place of typical multi-head attention in recent models such as the LLaMA-2 and Mistral7B.