
Linkedin has always been a active contributor to the opensource community. April 4th, LinkedIn announced a new opensource project Avro2TF
Avro2TF provides a scalable Spark-based mechanism to efficiently convert data into a format that can be readily consumed by TensorFlow.
As they explain it in Avro2TF official documentation: “To effectively support deep learning at LinkedIn, we need to first address the data processing issues. Most of the datasets used by our ML algorithms (e.g., LinkedIn’s large scale personalization engine Photon-ML) are in Avro format. Each record in a Avro dataset is essentially a sparse vector, and can be easily consumed by most of the modern classifiers. However, the format cannot be directly used by TensorFlow – the leading deep learning package. The main blocker is that the sparse vector is not in the same format as Tensor. We believe that this is not only a LinkedIn problem, many companies have vast amount of ML data in similar sparse vector format, and Tensor format is still relatively new to many companies. Avro2TF bridges this gap by providing scalable Spark based transformation and extensions mechanism to efficiently convert the data into TF records that can be readily consumed by TensorFlow. With this technology, developers can improve their productivity by focusing on model building rather than data conversion.”

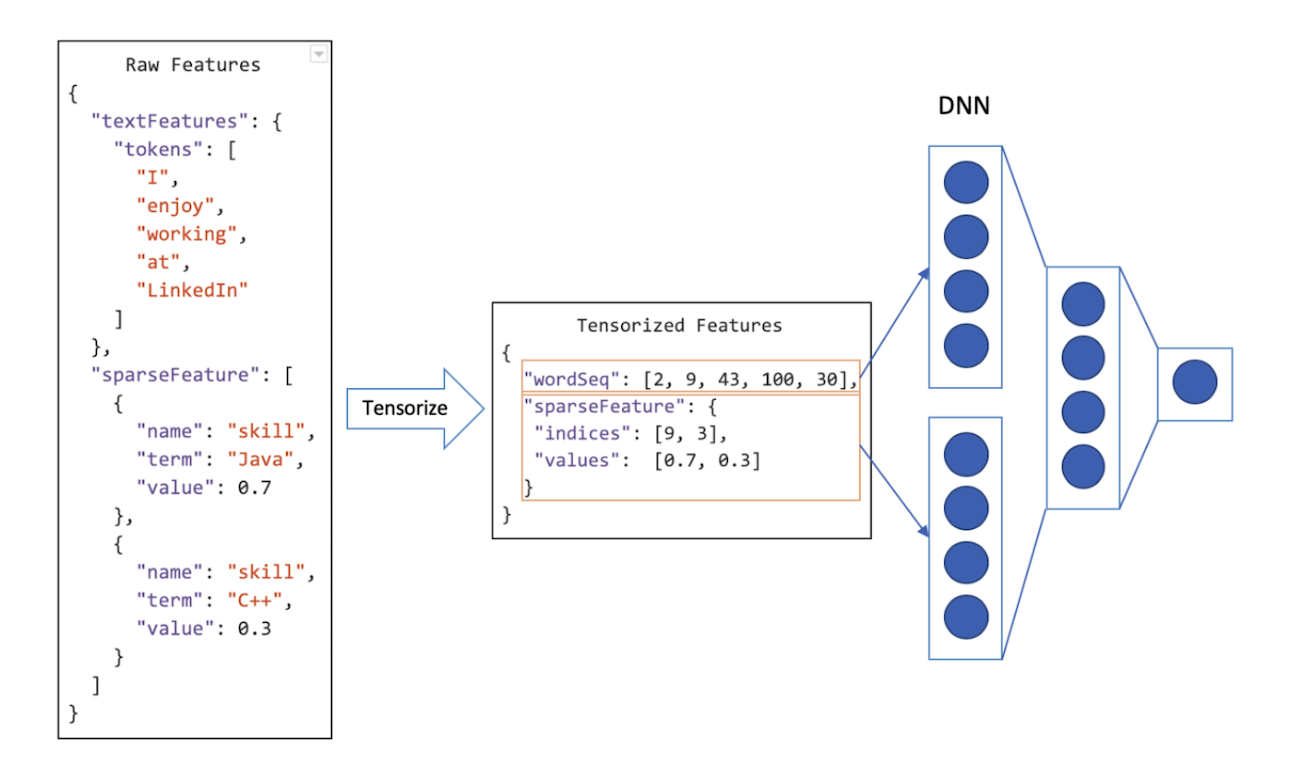
Avro2TF bridges the gap between the spark based data formats and tfrecords by providing a simple config for modelers to obtain tensors from existing training data. Tensor data itself is not self-contained. So, to be loaded to TensorFlow, it is required to carry metadata and Avro2TF fills this gap by providing a distributed metadata collection job.
- Avro2TF reads raw user input data with any format supported by Spark to generate Avro or TFRecord tensorized training data.
- Avro2TF exposes to users a
JSONconfig to specify the tensors that a modeler wants to use in training. For each tensor, a user should specify two kinds of information:
a. What existing features are used to construct the tensor.
b. The expected name, dtype, and shape of the tensor.
Avro2TF is completely built on Scala. To build Avro2TF from the repository, on your machine one needs to perform a Gradle build. To build Avro2TF, run:
./gradlew build
The jar required to run Avro2TF will be located in ./avro2tf-cli/build/libs/
But the best way to get started with Avro2TF is go with the Docker Image: to install and launch the Avro2TF Open Source Docker image.
In your terminal, run the following to launch a container for the docker image:
docker run -p 8080:8888 --name avro2tf-offcial-tutoriallinkedin/avro2tf-official-tutorial:latest
Copy and paste the URL into your browser to play with a Jupyter notebook. (Notice: Remember to change 8888 to 8080.)
Docker image from Docker Hub: Docker Image.
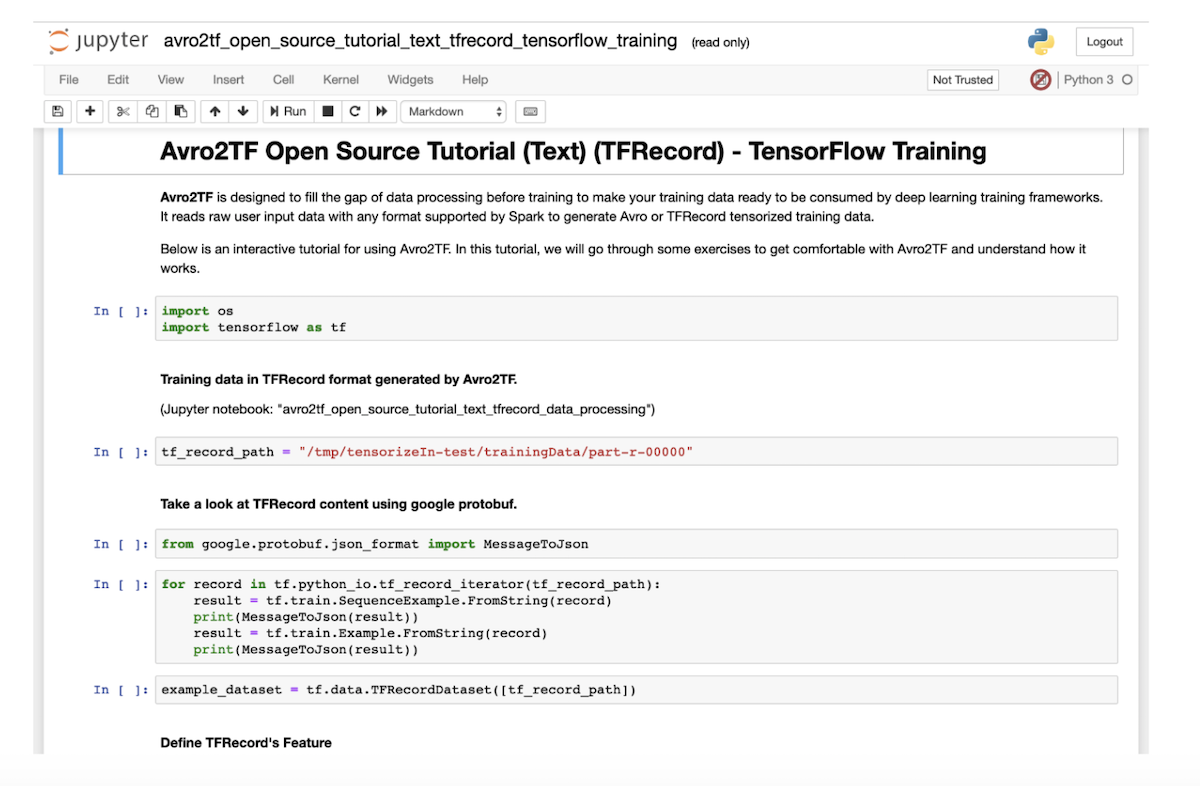
The jupyter notebook is the official tutorial for Avro2TF.
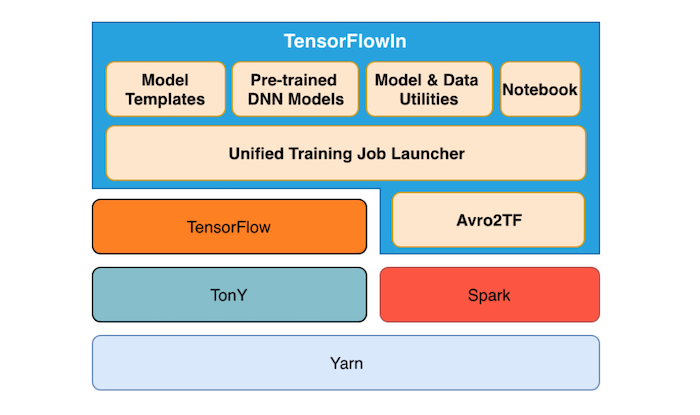
Inside LinkedIn, Avro2TF is an integral part of a system called TensorFlowIn that helps users easily feed data into the TensorFlow modeling process.
As mentioned on the official blog post: “TensorFlowIn is a deep learning training library that is compatible with TonY, TensorFlow, and Spark. It contains end-to-end training-related utilities and frameworks. The above figure gives a high-level overview of TensorFlowIn. Since large-scale data processing is an important step that is not only critical to many LinkedIn applications, but is also useful to the larger AI community, we decided to open source this engine after receiving positive internal feedback.”
LinkedIn has in past opensourced various other deeplearning tools like: PhotonML- Photon Machine Learning
Photon ML is a machine learning library based on Apache Spark. It was originally developed by the LinkedIn Machine Learning Algorithms Team. Currently, Photon ML supports training different types of Generalized Linear Models(GLMs) and Generalized Linear Mixed Models(GLMMs/GLMix model): logistic, linear, and Poisson.
and TonY: framework to natively run deep learning frameworks on Apache Hadoop.
TonY is a framework to natively run deep learning jobs on Apache Hadoop. It currently supports TensorFlow and PyTorch. TonY enables running either single node or distributed training as a Hadoop application. This native connector, together with other TonY features, aims to run machine learning jobs reliably and flexibly.
References and Learning Resources:
- Avro2TF Github Repo: https://github.com/linkedin/Avro2TF
- Avro2TF Official Tutorial: Avro2tf tutorial
- Avro2TF Linkedin Blogpost: Click here
- PhotonML: https://github.com/linkedin/photon-ml
- TonY: https://github.com/linkedin/TonY