
Training Large Language Models (LLMs)
Training large language models (LLMs) is typically a multi-stage process:
- Pretraining
- Supervised Finetuning (SFT)
- Preference Alignment
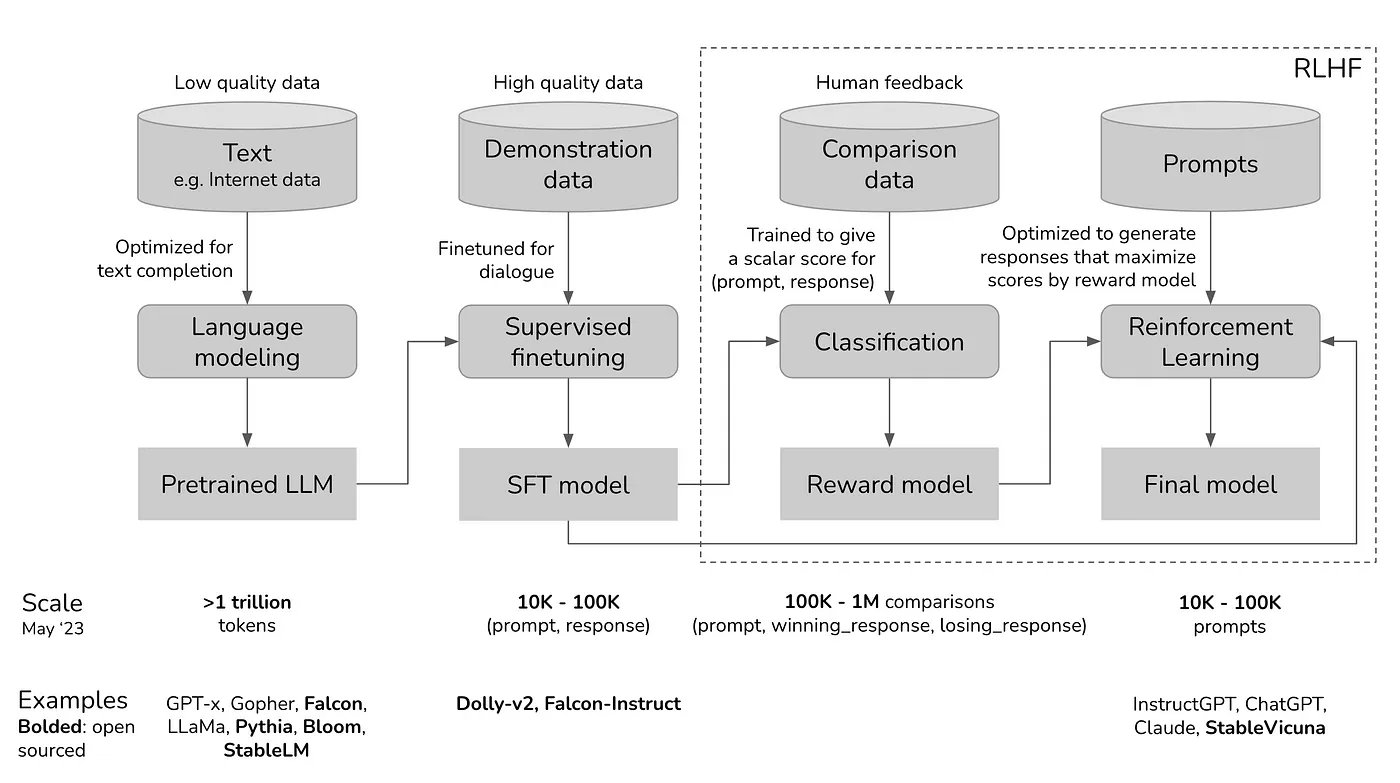
Pretraining is where it all starts. The model is fed massive amounts of web-scraped textual data using next token prediction objective to learn the fundamentals of language. It picks up on grammar, context, and even some common sense, giving it a broad understanding of how language works. By the end of this stage, the model can generate coherent text across various topics, but it’s still a generalist. To build instruction following agents (or conversational bots) the second stage — Supervised Finetuning (Instruction Finetuning) is performed. Here, the model is trained on specific datasets with task-oriented instructions. This stage refines the model’s ability to follow instructions, making it better at tasks like answering questions or summarizing text. Essentially, it turns the model from a general language generator into a more specialized tool for practical applications.
However, despite the ability to follow instructions, models may generate harmful, undesirable, unethical or not-so benign responses. To solve this perference alignment is performed as an additional step. Preference alignment fine-tunes the model to ensure it aligns with human values and avoids generating harmful or biased content. This is usually done with reinforcement learning from human feedback (RLHF), where the model learns to prefer outputs that human evaluators favor. The goal is to make sure the model not only performs well but does so in a way that aligns with ethical standards and user expectations. This is done on labelled / annotated datasets of preference pairs, where labellers select their preference answer or response for a given query. Apart from RLHF there are other techniques such as DPO, KTO, etc used for preference optimization.
ORPO: A Monolithic Preference Alignment Approach
Typically, preference alignment requires a reference model and a warm-up phase of supervised fine-tuning. To eliminate the reliance on the reference model and the multi-stage training process, ORPO proposes a monolithic approach. The authors aim to integrate preference alignment directly into the supervised fine-tuning (SFT) training, ensuring that the model can learn human preferences during the instruction tuning phase itself.
The paper (ORPO) emphasizes the importance of SFT in preference alignment, noting that a small penalty for undesired generation styles can be sufficient to guide the model. ORPO leverages this by using a straightforward odds ratio mechanism during SFT, which efficiently contrasts favored and disfavored responses. This method is designed to achieve stable convergence without the complexities and potential instability associated with reinforcement learning methods like PPO.
ORPO’s Approach
In traditional SFT, there’s no explicit mechanism to penalize the model for generating disfavored responses. ORPO introduces a method to directly contrast favored (chosen) and disfavored (rejected) responses by calculating the odds ratio.
Odds of Generating a Sequence
Odds of Generating a Sequence — The odds of generating a sequence $y$ given an input $x$ is defined as:
$$ odds_{\theta}(y \mid x) = \frac{P_{\theta}(y \mid x)}{1 - P_{\theta}(y \mid x)} $$
This helps quantify how much more likely the model is to generate the sequence $y$ compared to not generating it. Using these odds the authors define Odds Ratio (OR). The core idea of ORPO is to use the odds ratio to create a penalty that will encourage the model to favor the chosen response over the rejected one. The odds ratio between a favored response $y_w$ and a disfavored response $y_l$ is:
$$ OR_\theta(y_w, y_l) = \frac{odds_\theta(y_w \mid x)}{odds_\theta(y_l \mid x)} $$
This ratio directly compares how much more likely the model is to generate the favored response compared to the disfavored one. By optimizing this ratio, the model learns to increase the likelihood of generating preferred responses.
Loss Function: Combining SFT and Preference Alignment
The ORPO objective function combines the standard SFT loss (negative log-likelihood) with a penalty term based on the odds ratio. The SFT loss is the standard negative log-likelihood:
- Standard SFT Loss (negative log-likelihood):
$$ L_{SFT} = -\log P_{\theta}(y_w \mid x) $$
-
Odds Ratio-based Penalty:
$$ L_{OR} = -\log \sigma \left( \log \frac{odds_{\theta}(y_w \mid x)}{odds_{\theta}(y_l \mid x)} \right) $$
The penalty term L_OR is based on the log odds ratio, adjusted by a sigmoid function to smooth the gradient.
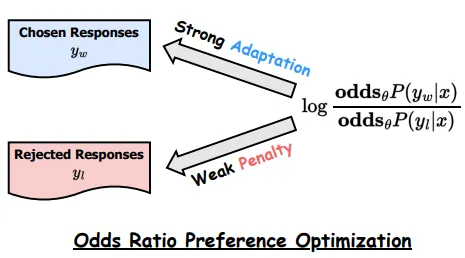
This term penalizes the model if the odds ratio between the chosen and disfavored responses is not sufficiently large.
The overall loss function is weighted sum of the two terms:
$$ L_{ORPO} = \mathbb{E}_{(x, y_w, y_l)} \left[ L_{SFT} + \lambda \cdot L_{OR} \right] $$
The objective combines the standard SFT loss with a new term that penalizes the model if it fails to differentiate sufficiently between favored and disfavored responses. The hyperparameter λ controls the strength of this penalty.
Results
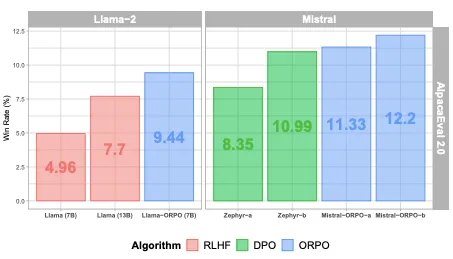
The authors performed various experiments on multiple LLMs ranging for 125M parameters to 7B parameter models. This includes Phi-2 (2.7B), Llama-2 (7B), and Mistral (7B). ORPO consistently improved performance, surpassing state-of-the-art models with significantly larger parameters. ORPO-tuned models, such as Mistral-ORPO-α (7B) and Mistral-ORPO-β (7B), achieved up to 12.20% on AlpacaEval2.0. In the MT-Bench multi-turn instruction-following benchmark, Mistral-ORPO-α (7B) and Mistral-ORPO-β (7B) scored 7.23 and 7.32, respectively, which are comparable to or better than a few larger models. They also performed experiments to evaluate diversity of response. ORPO maintained a good balance between per-input diversity (low within-input variation) and across-input diversity (high between-input variation).
In this article we will look a new LLM preference optimization approach ORPO: Monolithic Preference Optimization without Reference Model. Do checkout my other articles on LLMs, including Self-Extend, GQA, etc.
References
- ORPO: Monolithic Preference Optimization without Reference Model — https://arxiv.org/abs/2403.07691
- Training language models to follow instructions with human feedback — https://arxiv.org/abs/2203.02155