Till 2017, the domain of language modelling, sequence to sequence learning, language translation, image captioning where all dominated by RNNs and LSTMS. For example in a image captioning task you would have CNN based encoder and a LSTM based decoder. Though attention was introduced back in 2015, with NMT paper [Bahdanau et al., 2015] to overcome the fixed context vector drawback of traditional encoder-decoder architecture, it was not untill 2017 “Attention is all you need” paper that its full potential was explored. Transfomer removed the dependence on LSTMs, RNNs and CNNs by solely applying attention mechanism.
Transformer
What makes the transfomer architecture novel and the paper seminal is that it was the first proposed work that relied entirely on self-attention for the sequence to sequence learning task. Just like previous seq2seq learning architectures, that transfomer model is autoregressive at each step, which means that the predicted token is used as an (additional) input for generating the next token.
The basic architecture of transfomer can be divided into 2 parts:
- Encoder
- Decoder
Neither the encoder or decoder in this case is a CNN or RNN, both of them are composed of feed forward networks and multi-head attention blocks, which we will discuss further.
 Transformer model architecture from attention is all you need paper
Transformer model architecture from attention is all you need paper
Encoder
The encoder in the paper consists of N layers each layer having 2 sublayers:
- Multi-Head attention
- Feed Forward network
Each sublayers gets a residual input (Skip connection) from previous sublayer followed by a Layer Normalization. Layer normalization is different from batch normalization in the sense that input values for all neurons in the same layer are normalized for each data sample, unlike batch norm where input values of the same neuron for all the data in the mini-batch are normalized [J Lei Ba et.al].
The encoder takes as in the positionally encoded input embedding. In the paper the authors used a sinusoidal function to define the positional encoding. In language modeling transformers like BERT, GPT-2 etc they typically use fully learnable matrix inplace of the sinusoidal function.
$$PE_{(pos,2i+1)} = cos(pos/10000^{2i/dmodel})$$
$$PE_{(pos,2i)} = sin(pos/10000^{2i/dmodel})$$
Multi-Head Attention
The positionally encoded input embedding goes as input to the multi-head attention block. The Attention mechanism maps the key-value and query to the output. Query determines which words (values) to focus on (attend to). Both Key and Value are the sequences of input length. All key, value and query in case of the encoder, comes from previous layer of the encoder. In case of the decoder’s second multi-head attention sublayer query comes from the previous decoder layer, and keys an values come from the output of the encoder.
Scaled Dot-Product Attention
 {Bahdanau 2015} introduced the additive attention and {Luong 2015} introduced the dot-product attention. Transfomer uses the scaled form of the dot product attention. They used the dot product attention as it is much faster to computer with respect to the additive attention.
{Bahdanau 2015} introduced the additive attention and {Luong 2015} introduced the dot-product attention. Transfomer uses the scaled form of the dot product attention. They used the dot product attention as it is much faster to computer with respect to the additive attention.
The Query and Keys are multiplied ($QK^T$) and scaled using $\sqrt{d_k}$ where $d_k$ is the dimension of the keys, values and query vector. Masking is performed on this scaled matrix to ensure that the networks only sees the past values and not the future. Masking is performed by setting all the future values (above the main diagonal) in the matrix to $-\infty$. Softmax values are computed for the scaled query key products and multiplied with values.
$QK^T$ vector is scaled by $\sqrt{d_k}$ to ensure that dot product does not grow very large in magnitude and softmax doesnot have extremely small gradients.
$$Attention (Q,K,V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}}).V$$
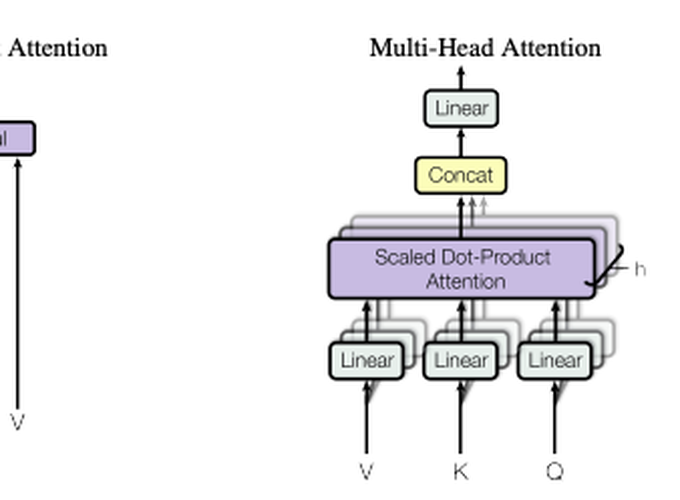
Multi-Head Attention:
The multi-head attention is formed by projecting the query, value, and keys h times using linear layers and then performing the scaled dot-product attention. The outputs from all heads are concatenated and passed through a linear layer. In the paper they use $h = 8$
