NAPReg: Nouns As Proxies Regularization for Semantically Aware Cross-Modal Embeddings
Abstract
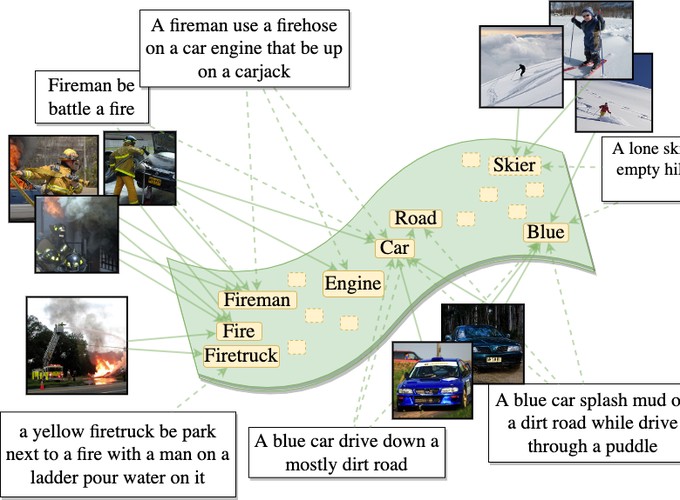
Cross-modal retrieval is a fundamental vision-language task with a broad range of practical applications. Text-to-image matching is the most common form of cross-modal retrieval where, given a large database of images and a textual query, the task is to retrieve the most relevant set of images. Existing methods utilize dual encoders with an attention mechanism and a ranking loss for learning embeddings that can be used for retrieval based on cosine similarity. Despite the fact that these methods attempt to perform semantic alignment across visual regions and textual words using tailored attention mechanisms, there is no explicit supervision from the training objective to enforce such alignment. To address this, we propose NAPReg, a novel regularization formulation that projects high-level semantic entities i.e Nouns into the embedding space as shared learnable proxies. We show that using such a formulation allows the attention mechanism to learn better word-region alignment while also utilizing region information from other samples to build a more generalized latent representation for semantic concepts. Experiments on three benchmark datasets i.e. MS-COCO, Flickr30k and Flickr8k demonstrate that our method achieves state-of-the-art results in cross-modal metric learning for text-image and image-text retrieval tasks.